Art 3D/VR challenge - week 1 - abstract overview

| Previous week | Next week |
Introduction
This article is continuation of Art 3D/VR challenge.
Please note, I don't describe all possible technologies, knowledge, science, models, and approaches you can find on the search engine.
The following information is my personal experience I have gained over the last 10+ years of my career. BY applying PRESENTED models and stack I can guarantee to achieve FAIR ENOUGH results.
Index
- Brief theory
- Hardware
- Software and standardisation
- Infrastructure and scalability
- Summary
BRIEF THEORY
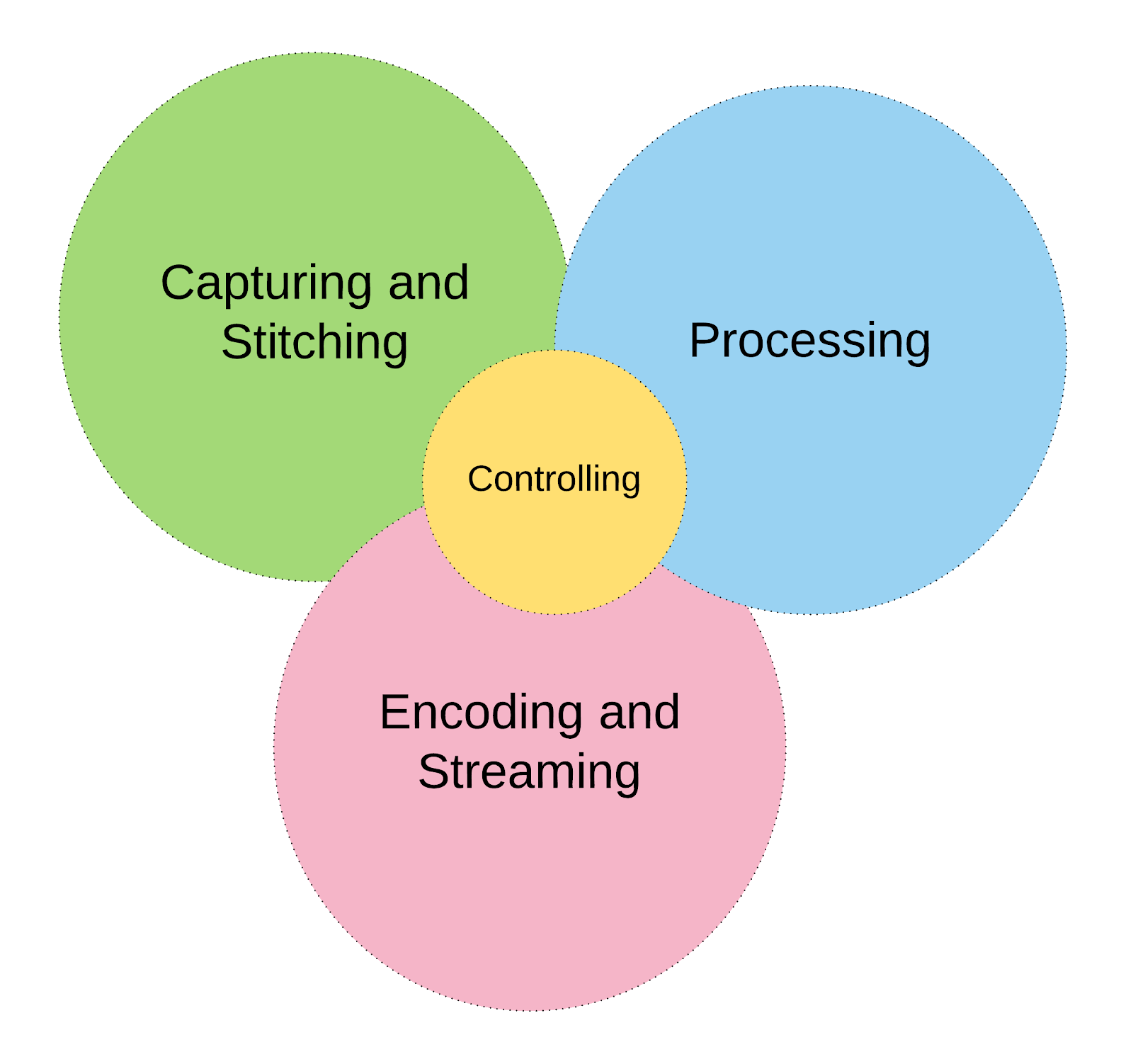
The chart above shows the most important 6 problems in 4 groups we would have to solve on the way from capturing a real scene up to the output as network packets or dedicated media interface. All groups will be described in more detail in the current blog post and the following one.
Brief definition of segments:
- Capturing - this segments describes lenses, cameras, mount setup, media format and output interface. This is important to provide the highest quality of image with the lowest possible noise. It also requires to provide the precision of optics and calibration for stereoscopic pairs of cameras. Low latency video processing (DSP), media format (RAW, MPEG) and output (USB/CSI, MPEG, RAW: 8/10/16 bits) will be very crucial on the media pipeline.
- Stitching - this segments describes techniques of media concatenation and multiplexing. By choosing the right techniques we will directly influence computation complexity, encoding latency and outgoing bitrate. It is very important to fully optimise this step. That process can be done on software level, on software/hardware level (GPU) and on hardware only level (e.g. CSI-2 multiplexer).
- Processing - this segments describes the set of techniques for multimedia processing (FFmpeg, Gstreamer)
- Controlling - this segments describes core business logic, APIs, provisioning, management and dynamic media pipeline optimisation (REST, Puppet, Ruby, GStreamer, FFmpeg etc.)
- Encoding - this segment describes techniques for software and hardware video/audio encoding (VP8/9, h264, AAC, MP3, Opus). It can be achieved by software, software/hardware (Video chipset / GPU) and dedicated hardware chipsets (e.g. DaVinci, OMAP) approach.
- Streaming - this segments describes techniques for integrating video/audio into media containers for network streaming (RTP, WebRTC) and digital media interfaces (DVI, HDMI, CSI, SDI). This process is relatively cheap in computation and can be done by software for network output and by dedicated hardware for analog/digital media interfaces.
By introducing 4 categories of problems I would like to put some light on the scalability and computing power distribution issues. Many use cases require sophisticated image processing, encoding and streaming which cannot be easily achieved on single CPU or GPU. By grouping specific problems we can distribute/clone video and audio on the computing cluster and distribute tasks by role. I will explain scalability problem in more details below and following blogposts. For now, please notice that the computing power is the top feature to achieve real time streaming and communication abilities.
Please note that the last segment of pipeline (which is not included in the chart) would be playback. I will explain the problem of playback and rendering to some extend below. However network latency, decoding, playback and VR/3D rendering is not the main topic of this challenge. I will provide external resources in this area of expertise.
Let's have a look on some vision theory...
Monoscopic vision rendering models and constructions
Monocular vision is vision in which both eyes are used separately. By using the eyes in this way, as opposed by binocular vision, the field of view is increased, while depth perception is limited. The eyes of an animal with monocular vision are usually positioned on opposite sides of the animal's head, giving it the ability to see two objects at once.
Monocular vision affects how the brain perceives its surroundings by decreasing the available visual field, impairing peripheral vision on one side of the body, and compromising depth perception, all three of which are major contributors to the role of vision in balance.
A monoscopic camera is characterized by having just one lens as opposed to stereoscopic cameras that have two:


Capturing models:

(source: google engine)
- 360° capturing model
A 360° video is simply a flat equirectangular video that is morphed into a sphere for playback on a VR headset. If a 360° video is monoscopic, it means that both eyes see a single flat image, or video file.
Monoscopic 360° videos are currently the most commonly filmed content for VR. This type of video is usually filmed with a single camera per field of view (FOV) and stitched together to form a single equirectangular video. Monoscopic videos have fewer technical challenges and are the easiest and cheapest to produce

(source: google engine)
- Sphere capturing model
The concept behind the spherical panoramas is nothing complicated, this technique is meant to reproduce in virtual reality (VR) the first person view taken in any direction at a certain instant. In simple words you have to take a lot of pictures all around, at full 360° on the horizon and also up (zenith point) and down (nadir point), and merge them into a single image.
Of course the problems appear when you try to merge the pictures together, indeed they have to be warped to match each other. A software could do that easily, but to do that it has to recognize the identical details in different images to overlap them. These identical details are named "control points" (CP). The more you overlap sequential images, the more CP you'll have. To be fair the number of CP is not as essential as their "quality".
Stitching a set of photos in a uniform single equirectangular image is totally a mathematical issue. In case you wondered what equirectangular means, this projection type is the most used way in VR to display a sphere on a plane, and if you'll manage to load it in a panorama viewer it will be certainly supported.

(source: google engine)
Stereoscopic vision capturing models and constructions
Stereoscopic videos are usually filmed with two cameras per field of view or one camera mapped to each eye, giving the perception of depth. While this experience is great when done correctly, it is much harder to get right. You will need to stitch camera footage for each eye separately and then create a side-by-side (SBS) 3D video mapping the left and right video to each eye. The SBS 3D video comes in a few configurations—top and bottom or right and left side-by-side. It is important to note that stereoscopic 3D decreases video resolution because the two side-by-side videos split the resolution of the screen.






(source: google engine)
Stereoscopic capturing can work with 360°, sphere or wide angle field of view. I will focus on wide angle capturing for simplicity as this is the case we would implement in the first generation of our device. Also I will present some concepts and tricks used by Virtual Reality products to gain lower bitrate, higher quality and better user experience overall.
Let's have a look on some of capturing models. There are many of concepts and tricks you could apply to achieve a very good results. There are models which fit very good for real-time communication, live streaming or simply recording. Latency of network, bitrate, encoding/decoding complexity and playback are the most common aspect we have to keep in mind. I will focus on models for real-time communication and live streaming on the first place.
- Full Real Image capturing and rendering
If a video is stereoscopic, it means there are two videos, one mapped to each eye, providing depth and 3D appearance.

(source: google engine)
- Green-Screen capturing and rendering model
Chroma key compositing, or chroma keying, is a special effects / post-production technique for compositing (layering) two images or video streams together based on color hues (chroma range). The technique has been used heavily in many fields to remove a background from the subject of a photo or video – particularly the newscasting, motion picture and videogame industries. A color range in the top layer is made transparent, revealing another image behind. The chroma keying technique is commonly used in video production and post-production. This technique is also referred to as color keying, colour-separation overlay (CSO; primarily by the BBC[2]), or by various terms for specific color-related variants such as green screen, and blue screen – chroma keying can be done with backgrounds of any color that are uniform and distinct, but green and blue backgrounds are more commonly used because they differ most distinctly in hue from most human skin colors.

(source: google engine)


(source: alicex.com)
This method is very popular and works perfectly for TV, movies industry etc. However for Virtual Reality effects and products it is not the easiest solution. It can work correct with dedicated setup but will not work in any random place and not in changing/mobile environment. Also complexity of the setup it too high to provide platform for start-ups and seed ideas.
Considering limitation of regular green studio setup I would like to propose next generation of "green studio" which would fit perfectly into VR environment...
- Intelligent Chroma Keying capturing and rendering model
I would like to specifically focus on this topic. The "Intelligent Chroma Keying" is not common used terminology. Regular green screen recording uses chroma keying for extraction green colour for further video processing.
Computing vision algorithms bring a new layer of image processing. It allows for accurate extraction of objects and accurate humans and objects tracking in real time. Integrating the OpenCV support for face tracking, objects tracing, template matching, pre-learning and grab-cut algorithms we can extract background/foreground from interesting us actions!
There are many methods for image segmentation. Below some of them:

(source: google engine)
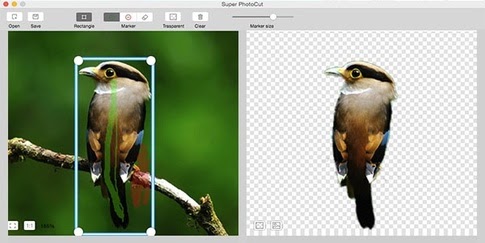
(source: google engine)
To achieve a higher level of accuracy I recommend to use depth camera which provides additional axis of information. It also significantly speeds up computation.
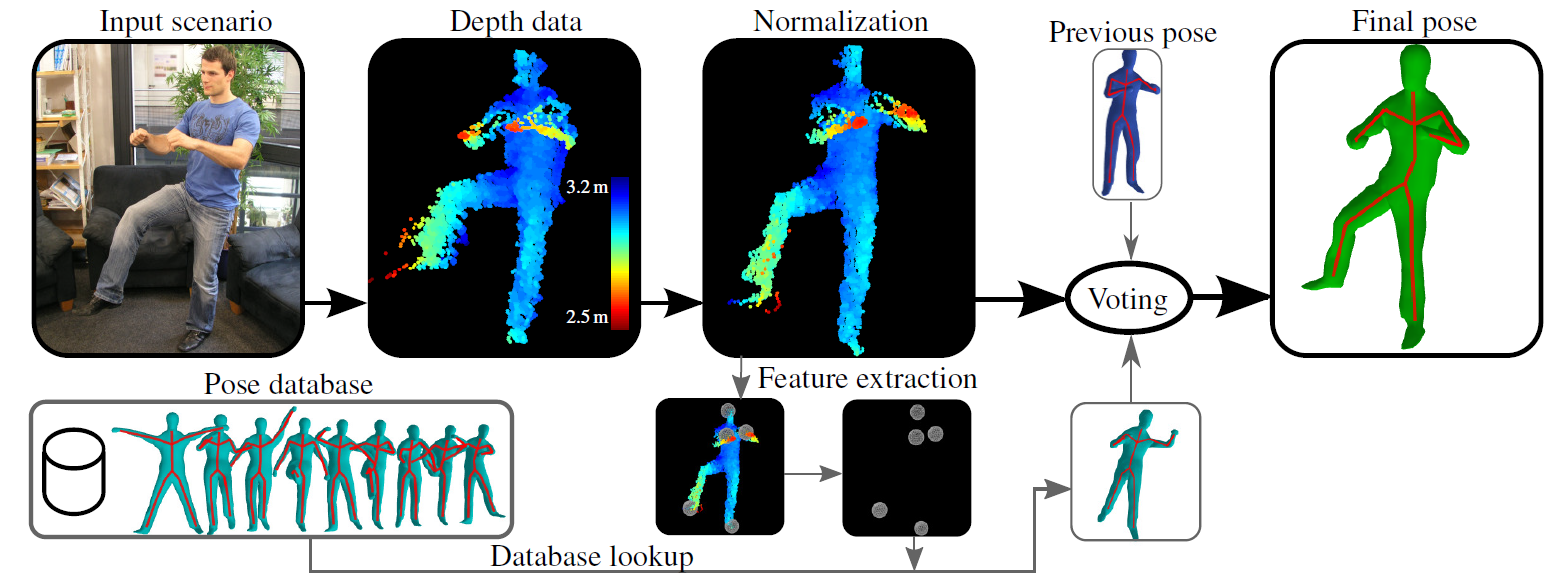
(source: seas.harvard.edu)
Next level of accuracy would introduce deep learning algorithm (e.g. DNN, ANN) for better understanding of objects in the scene.
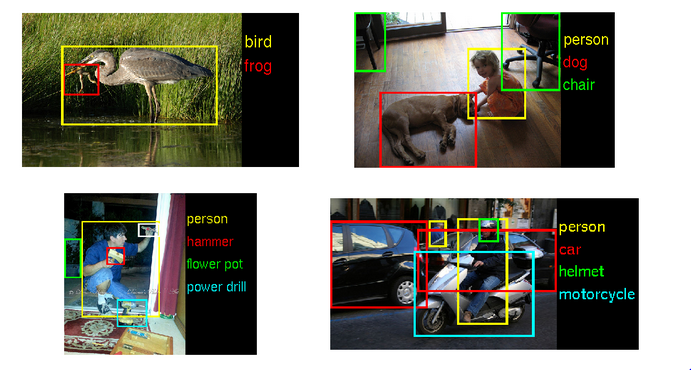
(source: google engine)
Unfortunately, the "deep learning" requires a lot of computing power. It will require another hardware board which would provide accurate information about the scene in real time.
Combining the simple faces and objects tracking, deep learning objects recognition, depth information and grab-cut algorithm we can implement a very accurate logic for removing a background and providing runtime information in real-time.
AT THE END OF THE DAY THE "INTELLIGENT CHROMA KEYING" IS ONE OF MAIN GOAL FOR THIS CHALLENGE. IT WILL ALLOW TO STREAM VR MEDIA FROM ANY ENVIRONMENT, REMOVE GREEN SCREEN COMPLEXITY, LOWER BITRATE, SAFE COMPUTING POWER ON ENCODING/DECODING AND PROVIDE EXTRA REALTIME INFORMATION ABOUT SCENE AND ACTIONS, AS WELL AS ALLOWING TO INTEGRATE VR MEDIA IN ANY VIRTUAL SCENERY ON THE PLAYBACK END POINT.
Equidistant stereo rendering vs Equidistant mono rendering
An equidistant stereo lens shader includes a user controlled device and an output device. The user controlled device includes one or more controllers, which are configured for orientation of a stereo field, orientation of a projection surface relative to a camera, use of converging stereo rays or parallel stereo rays, control over the zero-parallax distance for converging rays, and control over the interocular distance. The output device is configured to output left-eye images, right-eye images, or monoscopic images as equidistant fisheye projections.
Claims:
1. An equidistant stereo lens shader, comprising: a user controlled device, including one or more controllers configured for orientation of a stereo field, orientation of a projection surface relative to a camera, use of converging stereo rays or parallel stereo rays, control over the zero-parallax distance for converging rays, and control over the interocular distance; and an output device that outputs left-eye, right-eye, or monoscopic images as equidistant fisheye projections.
2. An equidistant lens shader process, comprising the steps of: controlling orientation of a stereo field; controlling orientation of a projection surface relative to a camera; controlling use of converging stereo rays, or parallel stereo rays; controlling a zero-parallax distance for converging rays; controlling an interocular distance; and outputting left-eye, right-eye, or monoscopic images as equidistant fisheye projections with the equidistant stereo lens shader of claim 1.
Read more:
Most up-to-date virtual realities are displayed either on a computer screen or with an HD VR special stereoscopic displays, and some simulations include additional sensory information and focus on real sound through speakers or headphones targeted towards VR users. The simulated environment can be similar to the real world in order to create a lifelike experience.

Summary - Where to go from here?
I recommend to have a look on eleVR blogpost and github source. There are tons of very useful informations, experiments, benchmarks, videos and articles. See some of them:
- http://elevr.com/tutorial-3d-spherical-camera-head/
- http://elevr.com/this-is-what-science-sounds-like/
- http://elevr.com/stereo-polygons/
- http://elevr.com/cg-vr-1/
- http://elevr.com/dont-look-down/
- http://elevr.com/updates-webvr-phonevr-wearality-kickstarter-etc/
- http://elevr.com/elevrant-360-stereo-consumer-cameras/
- http://elevr.com/10-fun-and-easy-things-that-anyone-can-make-for-vr/
- http://elevr.com/are-you-elevranting-or-am-i-projecting/
- http://elevr.com/editing-spherical-3d-in-premiere-and-after-effects-a-design-document/
HARDWARE
Lenses

(source: google engine)
- Mount type: M12 recommended for the portable, small device
- Distortion level: should be lowest possible
- FOV: horizontal, vertical should be highest possible 180°+ with minimal distortion
- Resolution: 5M+ is recommended
Camera
- Noise: lowest possible
- Sensitivity: highest possible
- Focus: manual should be efficient
- Interface: USB 3.0 or CSI-2
- Output format: RAW recommended
CPU

(source: google engine)
- ARM Cortex-7, ARM Cortex-9, ARM Cortex-15, ARM Cortex-57
- Intel Skylake, Broadwell
- Intel Xeon
GPU

(source: nvidia.com)
Any of the latest chipsets will work for this project. We have to make sure that the size of this hardware is reasonable (small fan or radiator).
Interfaces
Hardware acceleration
Chipset for encoding, decoding and video transformations.
SOFTWARE AND STANDARDISATION
Frameworks
MultiMedia framework
Software heart of the platform will be multimedia framework. We look for the realtime computation, clean API, easy integration on libraries level, high coverage of formats and codecs. There are many of frameworks which allows to process media in very sophisticated manner:
From my personal experience the best would be cross platform ready and open source GStreamer. Mainly because it implements clean separation between core and tons of plugins, is easy to extend with custom plugins and provides wrapper for almost every other media framework like OMX, FFmpeg and technologies in area of 2D/3D processing and computing vision.
3D Graphic framework
3D graphics have become so popular, particularly in video games, that specialized APIs (application programming interfaces) have been created to ease the processes in all stages of computer graphics generation. These APIs have also proved vital to computer graphics hardware manufacturers, as they provide a way for programmers to access the hardware in an abstract way, while still taking advantage of the special hardware of any specific graphics card.
For current project I will use OpenGL as I have gain enough of experience in that area. Also there is very good GStreamer (multimedia framework) integration.
Computer vision framework
Computer vision is a field that includes methods for acquiring, processing, analyzing, and understanding images and, in general, high-dimensional data from the real world in order to produce numerical or symbolic information, e.g., in the forms of decisions. Understanding in this context means the transformation of visual images (the input of retina) into descriptions of world that can interface with other thought processes and elicit appropriate action
This technology is extremely important for implementing "Intelligent Chroma Keying" which is the top goal of the challenge. I will use OpenCV as I have gain enough of experience in that area. Also there is good support with media frameworks and hardware acceleration (with GStreamer, CUDA).
Parallel computing framework
Parallel computing is a type of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved at the same time.
In this challenge, extremely high computation in parallel will be used scene recognition, objects tracking and accurate segmentation.
Neural Network framework
Deep learning (deep structured learning, hierarchical learning or deep machine learning) is a branch of machine learning based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations.
Various deep learning architectures such as deep neural networks, convolutional deep neural networks, deep belief networks and recurrent neural networks have been applied to fields like computer vision, automatic speech recognition,natural language processing, audio recognition and bioinformatics where they have been shown to produce state-of-the-art results on various tasks.
In this challenge the goal would be to use high efficient GPU to solve more complex problem of scene segmentation by continues learning.
STANDARDISATION
Digital video standards
- 4K, HD, FullHD, UltraHD
- Ratio: 16:9, 4:3
- Colors: RGB, YUV, YUVA, RGBA etc.
- Format: RAW, MPEG
Network protocols
The device will be fully controlled over network interface. It will allow to manage configuration, read state and push media data. The stack which we are gonna to use:
- RTP + (de)payload, WebRTC - multimedia streaming and communication
- HTTP, WebSocket - configuration, signaling and API
- STUN/TURN - support for WebRTC technologies and RTP
Operating System
- Linux distribution: Ubuntu recommended. Why? It provides software packages for all technologies required by project.
- Technologies: VAAPI, VDPAU, AV, GLX required
Controlling
Another piece of software we will have to handle is the management and controlling. This is relatively easy part which will provide the business logic for controlling the multimedia pipeline from outside the device. We can consider multiple approaches but the most common one will be:
- REST API
- Web UI
- CLI tool
INFRASTRUCTURE AND SCALABILITY
Computing power distribution
Various hardware and software architectures are used for distributed computing. At a lower level, it is necessary to interconnect multiple CPUs with some sort of network, regardless of whether that network is printed onto a circuit board or made up of loosely coupled devices and cables. At a higher level, it is necessary to interconnect processes running on those CPUs with some sort of communication system.
In case of video processing/distribution we have to introduce more sophisticated controlling rules. On one level we have to clone media and distribute on the topology and on another level we have to take care of signaling and media pipeline controlling.
I would suggest to consider following concepts:
- Horizontally via Video signal (HDMI, SDI, CSI-2)
- Vertically via GPU opengl/shaders (Nvidia, AMD, Intel)
- Vertically via Hardware acceleration (CPU/Skylake)
Basically we have 2 ways to scale: horizontal which is more preferable and vertical which has many limitations. Each methods introduce hardware and controlling complexity.
In my opinion the "Horizontally via Video signal" is the best option to scale "infinitely".
Provisioning and management
IT automation software that helps system administrators manage infrastructure throughout its lifecycle, from provisioning and configuration to patch management and compliance. Using management tools, you can easily automate repetitive tasks, quickly deploy critical applications, and proactively manage change.
SUMMARY
What is the best combination?
Finally we went through tons of science, techniques, technologies, software and hardware! We can transform the initial abstract chart (with segments) into more detailed workflow of information (scene) through hardware and software up to the playback system.
Presented diagram shows stereoscopic input, business logic and output via digital media interface or network protocols:
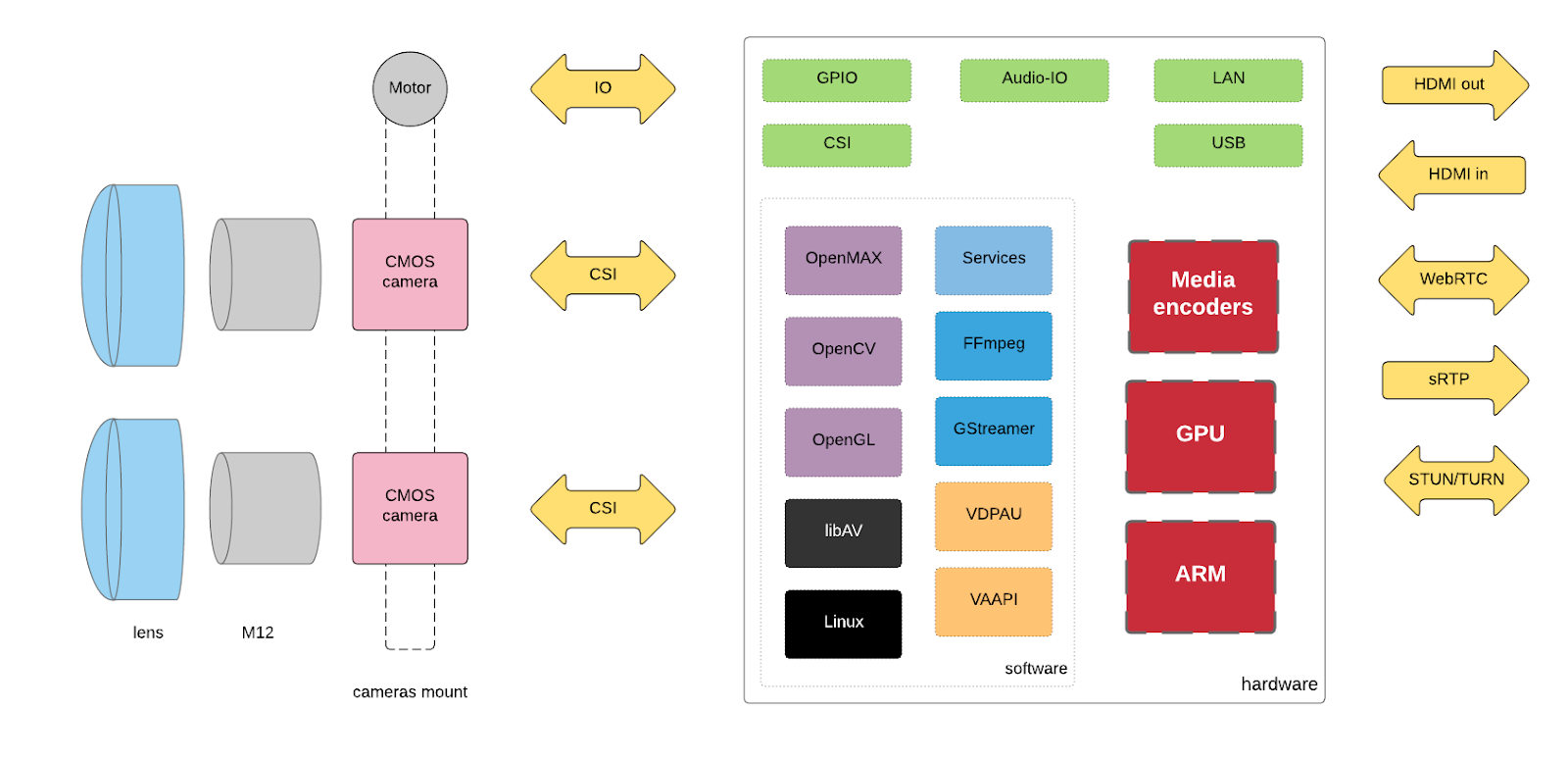
In the following blogposts/articles I will focus on each part in details on the hardware and the software level.
Next step
During the next week I will focus on looking into the performance characteristics and development kits (CPU, GPU etc) currently available on the market...
Topic: Art 3D/VR challenge – week 2 – Looking for performance
Contribution
Feel free to contact me if you are interested in meeting the team and contribution to this project in any programming language (go, php, ruby, js, node.js, objective-c, java...). This project is parked on Github.
See my contact page if required.
Resources
Multiple parts of my blogpost have its source in remote articles, blogposts and wiki for which I have no rights. I am not able to link all external sources to my blogpost. I would like to say thank you to everyone who shares the knowledge publicly. If you think I have illegally used any of your thoughts, products, patents please let me know and I will fix the issue asap.
© COPYRIGHT KRZYSZTOF STASIAK 2016. ALL RIGHTS RESERVED



Comments