Intelligent Content Streaming Engine (ICSE) - Part 1 / Introduction
Statements
“Intelligence is an ability for slow forgetting”
“Lazy neuron, great intelligence”
“The environment and the Viewer place in that environment is the key player of the prediction game and is the only true and correct point of view for personalised computation of the information”
“The prediction of valuable information for specific User as an average of all Users feelings to the specific information is as same useless as prediction of weather for specific location as average of weather for all known locations”
Introduction
For a last year I am implementing Artificial Intelligence science achievements into the real world, specifically into the web world. As there are many running projects I would like to add some of my personal observations and solutions in that matter.
My main goal is to reduce the stream of useless informations received by everyone, everyday, everywhere!
read more about my motivation and point of view
Proposal
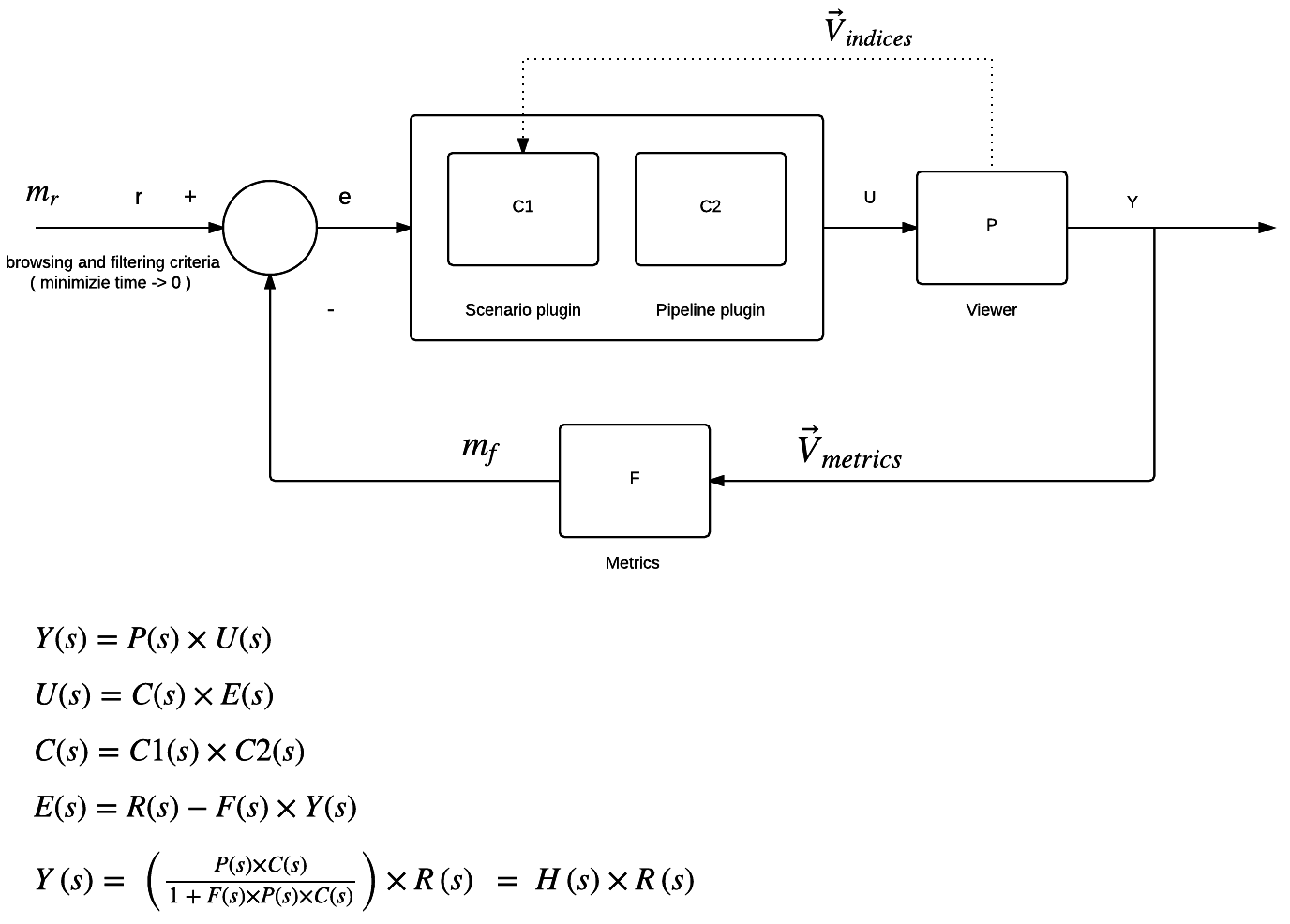
I would like to propose the Data Prediction Workflow Model which is able to solve known problems of Streaming Personalised Content to the Viewer at the specific location, environment and point in time via the world web! This model is also able to forecast upcoming Viewer needs.
On the abstract level the workflow pipes all streamed data through predefined plugins like ANN, SVM, Filtering etc. before it actually arrives to the Viewer. The intelligence for pipeline plugins comes from metrics collected on the Viewer UI.
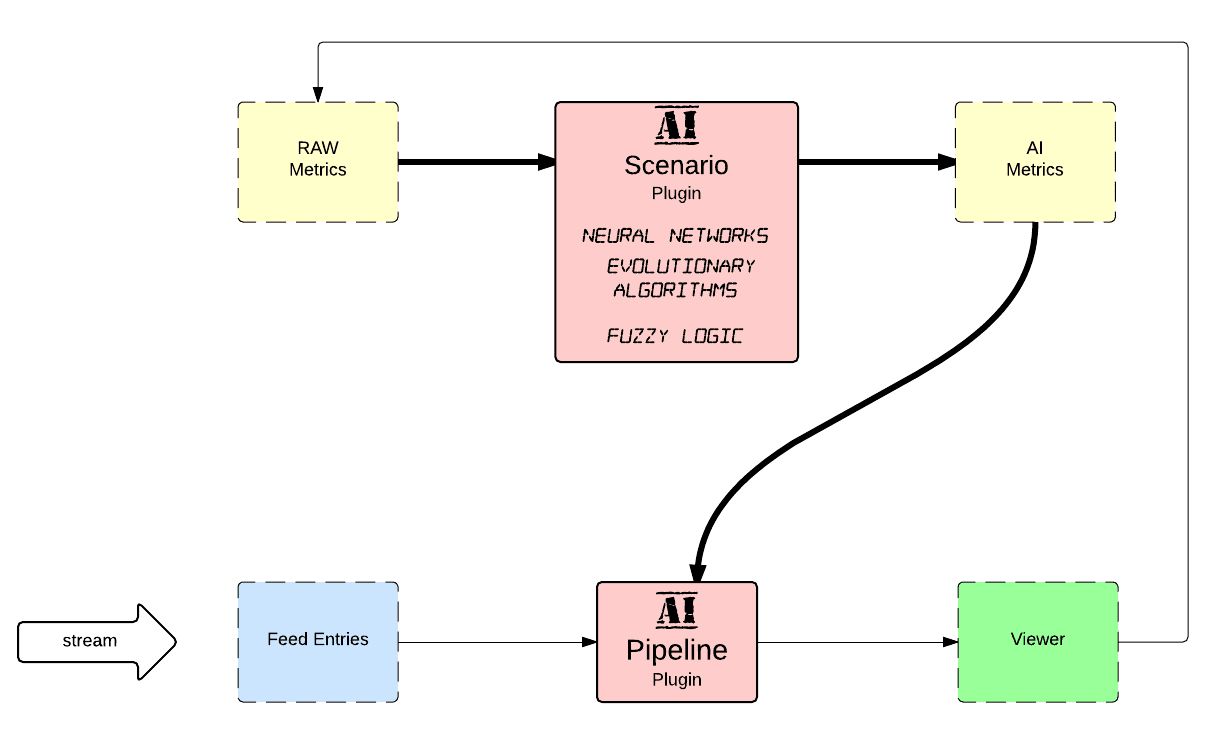
Estimated transmission model of learning is like follows
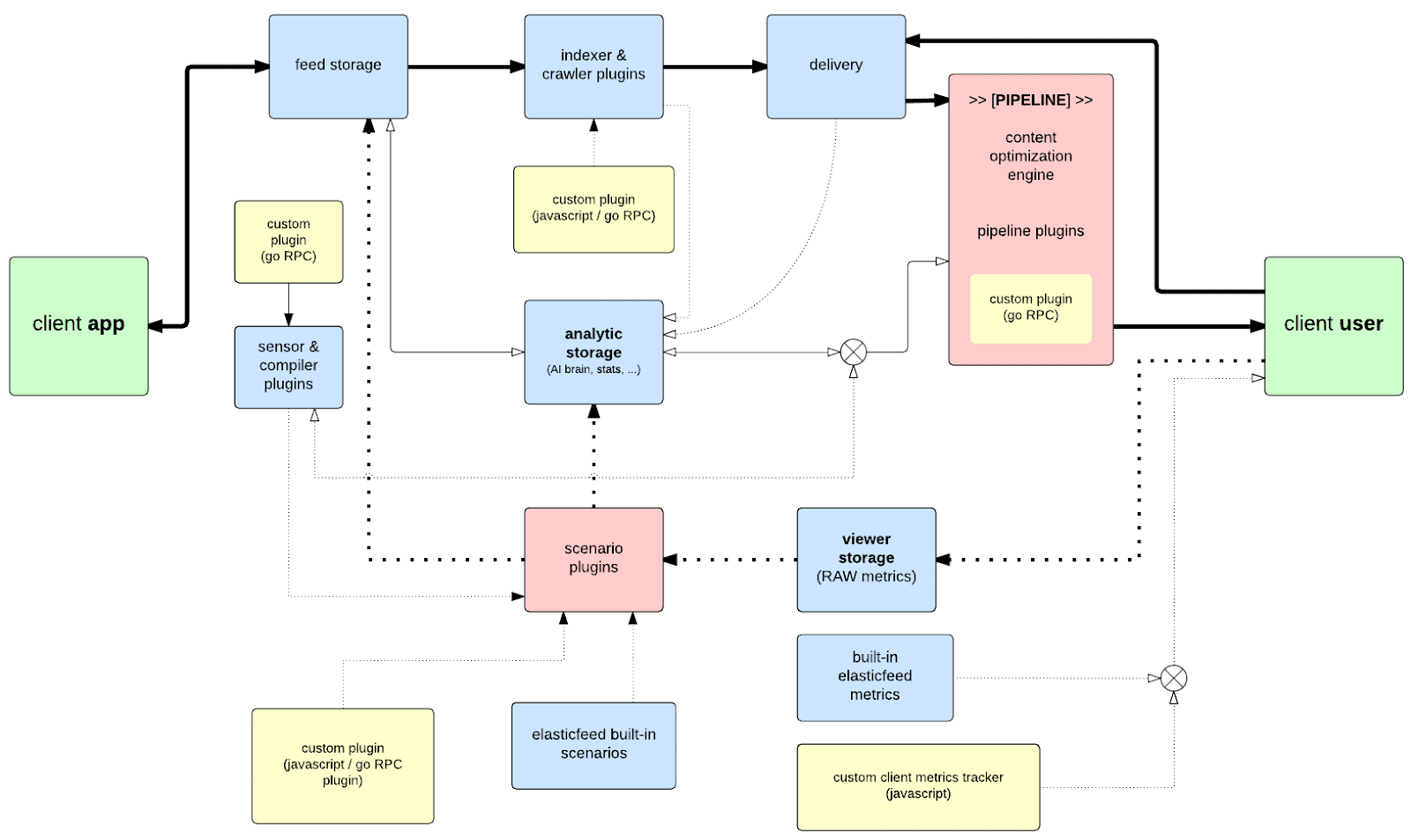
ICSE architecture
Intelligent Content Streaming Engine is the platform for Storing, Processing, Distribution and Learning about Viewer to Content interactions within specific environment. The core components are indexers/crawlers for pre-learning, pipelines for intelligent delivery, scenarios for “intelligence” evolving and sensors for detecting the viewer environment.
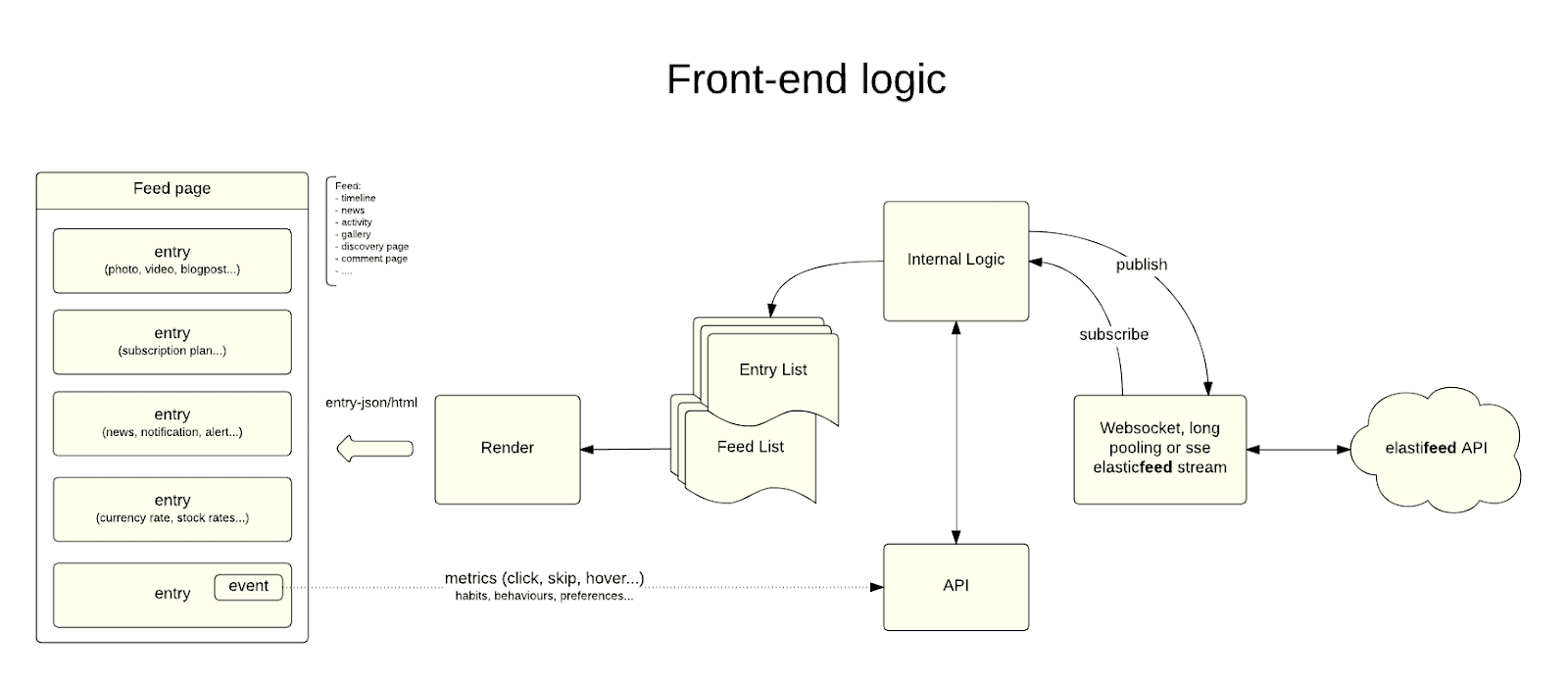
The engine works in server-client communication model where server stores content as item called “ENTRY” on the list called “FEED” which has own representation on the client UI as the “FEED PAGE”. Communication between server and client instance of “FEED” is bidirectional per Viewer.
Engine workflow
storing - is pre-learning about content
processing - is maintenance process for cleaning, growing, rebuilding content
distribution - is intelligent content delivery which combines viewer profile and pre-learned knowledge about content
learning - is evolving process based on viewer and content interactions
The server engine orchestrates basic gears like resource manager, service manager, workflow manager, plugin manager, event manager, cluster manager and manages internal communication.
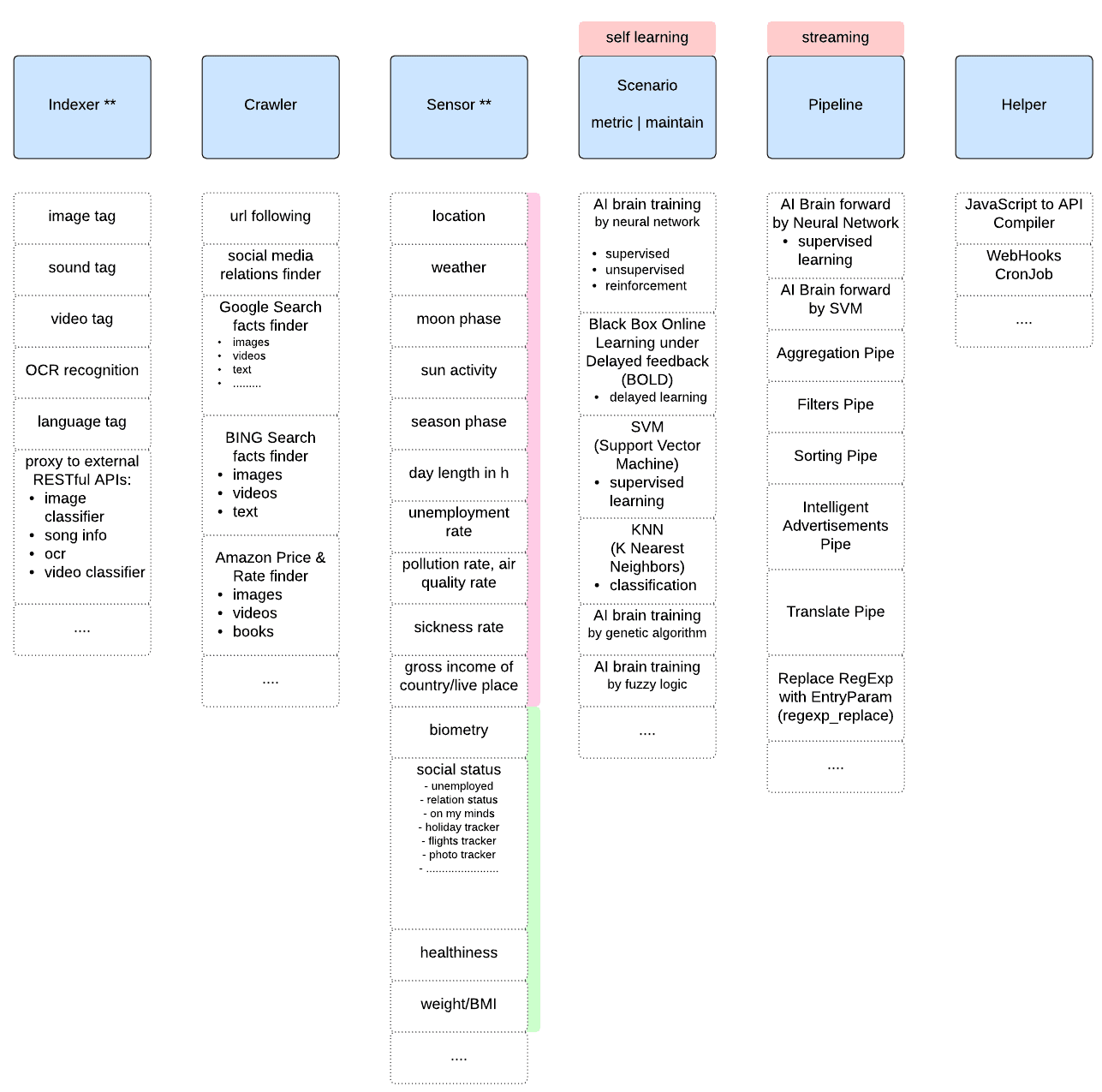
Components
indexer & crawler - provides indices and metrics about content
sensor - provides informations about viewer specific environment
pipeline - filters content by combining sensors knowledge, content knowledge and viewer profile knowledge (e.g. neural network, svm, bold, filtering, sorting) before pushing to the viewer UI.
scenario - builds knowledge about viewer profile by combination of sensor knowledge, content knowledge and viewer actions (e.g. neural network supervised learning)
Components are packaged as the binary plugins and work separately from engine. Communication is done by RPC and allow for distribution of computation across the cluster. Excluding plugins from engine allows for easy resource management on the OS level for each plugin instance (cpu, ram, networking, hd/).
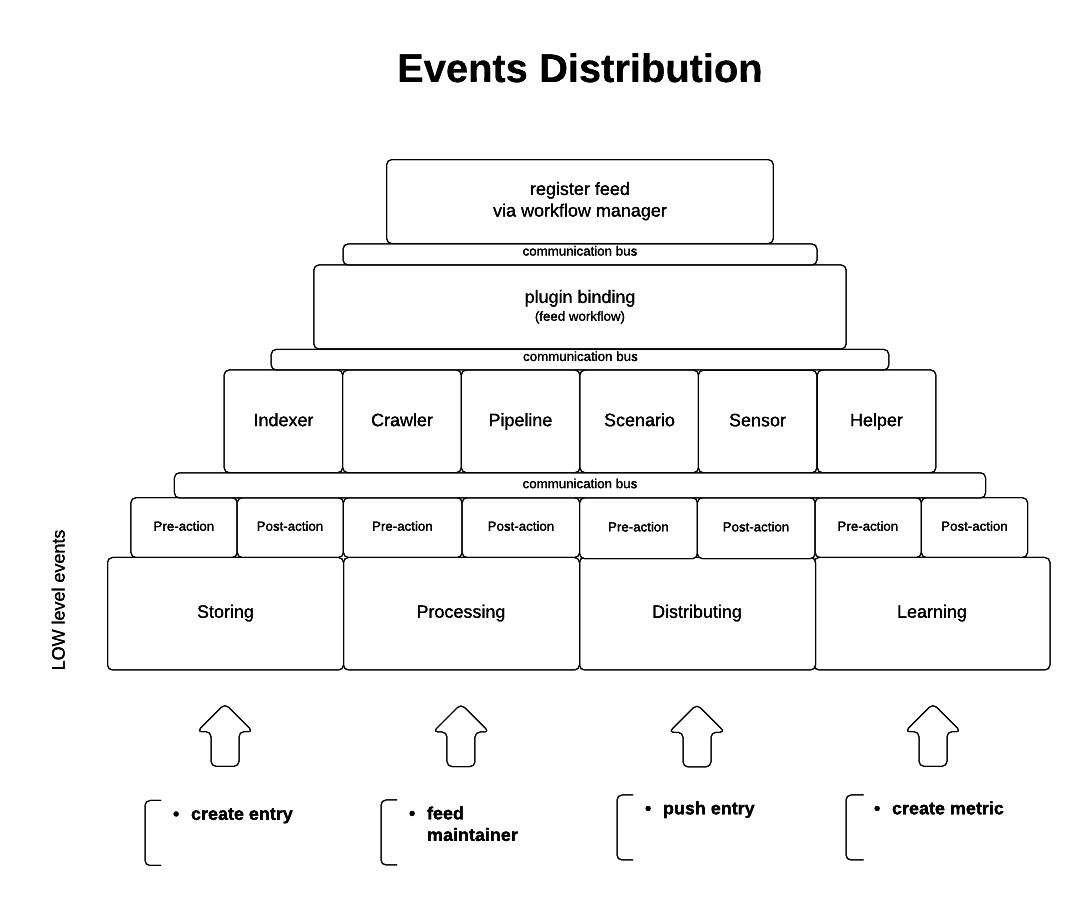
Events distribution
System Events Management is the key feature of data flow control. It allows for centralised distribution of events during full learning cycle. ICSE implements various low level events and hooks:
new entry - triggered when new entry is added to the feed list
new viewer - triggered when new viewer binds to the feed list
new metric - triggered when new viewer actions comes from the UI to the engine
feed maintainer - triggered periodically; defined by sysadmin or workflow
sensor update - triggered periodically; defined by sysadmin or workflow
push entry - triggered as hook for each viewer UI request
Events are triggered by any of low level engine gears like: resource manager, service manager, plugin manager, workflow manager etc.
Services
store - backend API for application
stream - frontend API for delivery and metrics
metric - backend API for metrics
system - backend API for engine management and monitoring
Service manager takes care of monitoring and scalability of specific services.
Workflows
flow - defines routes for data through the plugins chain for predefined hooks and events. Allows to limit resource usage for specific plugins.
hooks - binds to stream and store service events
events - bind to global system events
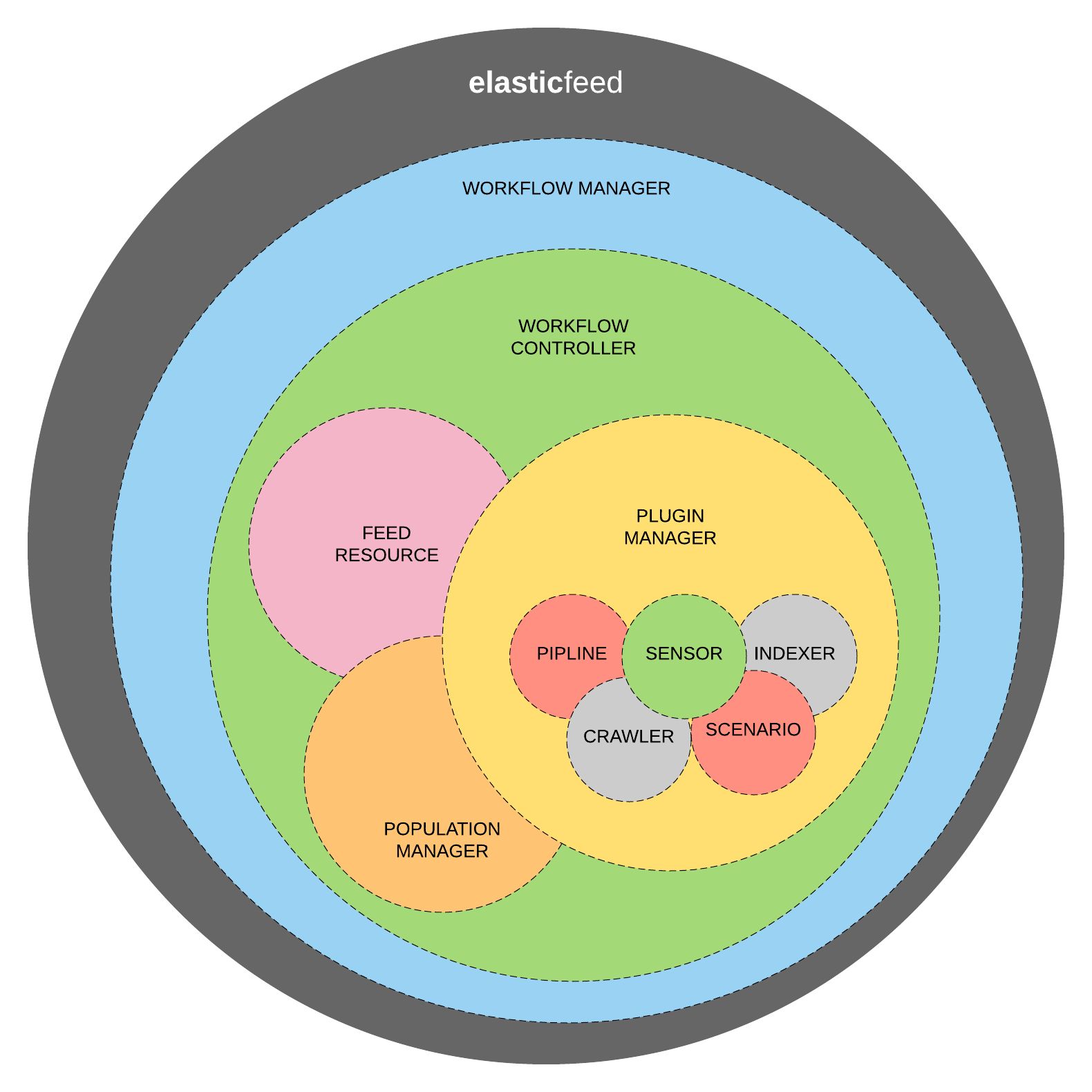
Workflow manager takes care of piping data through defined plugins. It binds deeply to system event manager, stream service and takes care for all "FEED" events on the back-end and front-end.
Progress
Heavy prototyping and development of this engine has started on April 2014 and is the running process. Stable beta version will be released shortly as open source...
Technologies
Golang written
Db: neo4j adapter (current)
Streaming: websocket, sse, long pooling
- APIs: RESTful
Platforms: Mac OS, Linux, Windows
Backend SDKs: PHP, Ruby (current)
Frontend SDKs: JS (current)
CLI tool (rubygem)
Contribution
Please contact me if you are interested in meeting the team and contribution to this project in any programming language (go, php, ruby, js, node.js, objective-c, java...). This project is parked on Github and will be hosted at elasticfeed.io
See my contact page or please leave your e-mail address here if you want be notified when the open source is released.
© COPYRIGHT KRZYSZTOF STASIAK 2015. ALL RIGHTS RESERVED

Comments